AWS Global Accelerator for blue-green deployments
And why solutions from services such as Route53, CloudFront, and ALB didn't make the cut.

Zero downtime.
You have an old application. You want an updated application. You start it up with no traffic and make sure it works. You gradually shift traffic from the old one onto the updated application until all the traffic is on the new app.
Done!
…how does it get done, though? Well, in AWS, there are a few relatively well-known options:
All of these are valid options depending on the architecture of the application. However, my team and I had a use case that none of these solutions really solved well. After several whiteboard sessions, proof of concepts, and tireless Google/Stack Overflow searching (ChatGPT wasn’t a thing, yet), we finally stumbled upon an AWS service that was a near-perfect solution; one that we had never even heard of before: AWS Global Accelerator.
Why the well-known options didn’t work
Before jumping into the solution, let’s establish some context on how we got there.
Our application was a collection of microservices in a Kubernetes cluster that we managed on EC2 instances using kOps. Our end goal was to perform a zero-downtime migration of these microservices from this cluster to a new EKS cluster. We also wanted the ability to test our new cluster ahead of time and target requests at it directly, independent of any sort of randomized or algorithmic routing along the way.
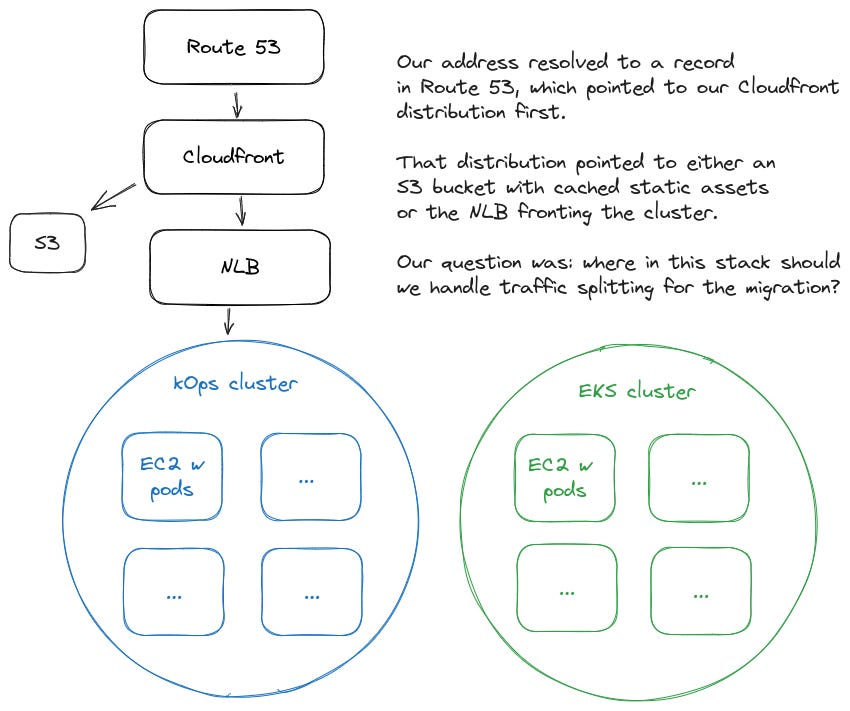
At face value, it seemed like one of the well-known approaches would just work. However, there were limitations with each one of the options for a clean zero-downtime migration.
Route53 weighted routing
This option is fairly simple - in your record set, you can set the routing policy to weighted and specify your resources. The main caveat to this approach is you are at the mercy of DNS in this scenario.
Let’s say you want to distribute a small percentage of traffic over to the new EKS cluster, but it has some issues and you have to rollback all traffic to the old endpoint: would the change be instantaneous?
Unfortunately not. Since we can’t control what type of DNS caching our clients have set, they may continue to hit the new, faulty endpoint until they pick up on our rollback to the old endpoint.
ALB weighted routing
This is a reasonable option - an application load balancer (ALB) can split traffic between two different targets like our kOps cluster and new EKS cluster. The problem was our cluster was fronted by a network load balancer (NLB) and we didn’t have an existing ALB to achieve this.
Theoretically, it would have been possible to stick one ALB in front of the two NLBs - an NLB for our kOps cluster and an NLB for our EKS cluster. But this would have introduced a few more complexities:
SSL encryption: we had end-to-end encryption utilizing SSL passthrough with the NLB. But introducing an ALB would require us to perform SSL termination there and complicate our security posture on that front.
Infrastructure-as-code: it wasn’t clear how we were going to set up the ALB. Would we just set it up with Terraform as a static resource to front the two NLBs? Or would we try to utilize something like the AWS ALB Ingress Controller?
NLBs as targets: This was a no-go! AWS doesn’t allow NLB as a target from an ALB.
CloudFront Continuous Deployment
We really wanted this one to work! It was released around November 2022 and the timing couldn’t have been better - we were about a month or so away from our deadline for the migration.
In your Cloudfront configuration, you could create a staging distribution and point a percentage of traffic at that endpoint - in our case, our new EKS cluster!
However, the main limitation of this solution was the inability to forward ALL traffic over to the new endpoint. At the time of this implementation and of writing this blog, you could only forward 15% of traffic. This is useful for a canary deployment strategy when you’d like some initial feedback on a change, but we weren’t confident enough to jump from 15% to 100% in a full swap. We wanted to have absolute control over dialing that weight.
Enter AWS Global Accelerator
After a few demoralizing afternoons of whiteboarding and ruling out the above solutions, we were starting to run out of ideas. Luckily, I happily stumbled upon a post from AWS when looking for alternative solutions to our problem.
What is AWS Global Accelerator?
Typically, AWS Global Accelerator is used to improve network latency and reliability for applications. If Global Accelerator is enabled on whichever endpoint you choose - say an ALB, EC2 instance, etc. - a user request will go to an AWS edge location first and then be routed through the AWS network. This is presumably much better than having your traffic routed through the regular hops you’d jump through on the public internet.
How does it work for zero downtime deploys?
Global Accelerator has endpoint weights, which allows you to specify two endpoints for your application and specify a value between 0 and 128 - where 128 would be 100% of the traffic (I was amused that it wasn’t percentage-based).
In our case, we were able to specify the addresses of our NLBs as the endpoints for Global Accelerator and gradually increase the EKS cluster endpoint while decreasing the kOps endpoint. Once we did that, we pointed our Cloudfront distribution to the Global Accelerator address instead of the NLB address for our kOps cluster.
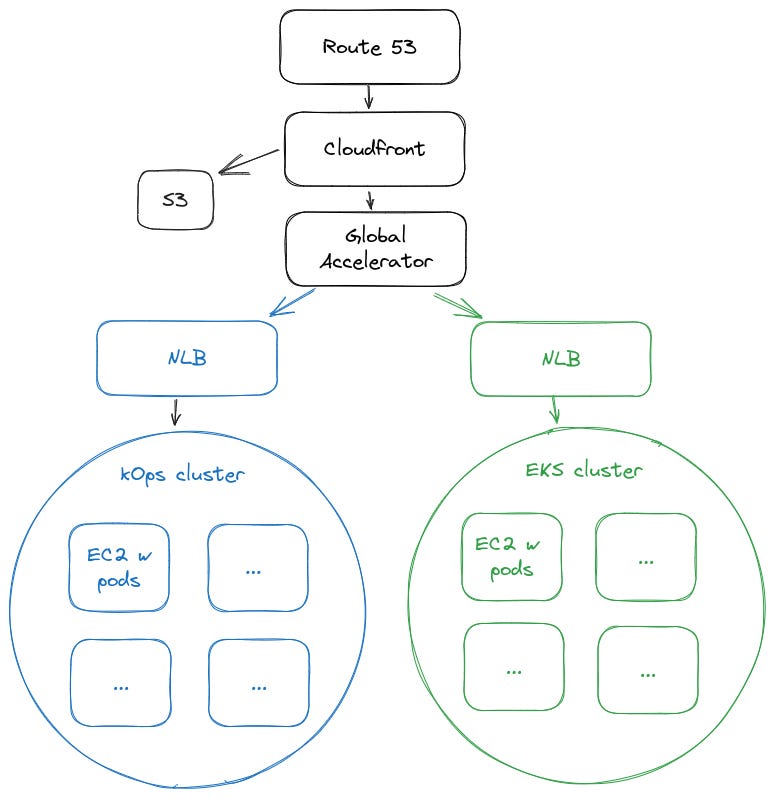
This architecture also allowed us to point requests at a specific NLB using Lambda@Edge, where depending upon the source IP of the request, we would forward you to a specific NLB endpoint instead of going to the Global Accelerator address.
For a detailed explanation of how to set it up the endpoint weights in Global Accelerator, check out this blog post: Using AWS Global Accelerator to achieve blue/green deployments
Conclusion
Global Accelerator worked like a charm! We were able to migrate several Kubernetes clusters with thousands of pods servicing millions of requests per day without any downtime using this solution.